Recently on CrossValidated, a user asked about why one might prefer to use an EM-algorithm over gradient descent for the computing the MLE in the case of mixture models. As it turns out, some of the work I have done on icenReg happens to directly answer a special case of this question!
Before I start in on this, I will state my biases on gradient descent as a general method. Many computational statisticians are annoyed with the recent rise in popularity of the method, almost certainly due to Andrew Ng's Coursera courses on Neural Networks and it's world-wide popularity. On the other hand, many of those who consider themselves data scientists love the algorithm; it's kind of a one-size-fits-all algorithm (seeing "one-size-fits-all" as a good think vs. a bad thing may be a defining difference between statisticians and data scientists?), typically of order O(nk) per iteration in most problems, easily run in parallel and easy to implement. I suppose I sit in middle of these views; I agree with the statisticians that in general, it is a very simplistic, inefficient, undeservingly popular algorithm at this moment in time. However, I also believe there are plenty of people that consider themselves data scientists, use gradient descent and it's the right thing to do for that problem. I clearly don't hate the algorithm too much, as I put my name on an algorithm that has a constrained gradient ascent step in it.
Okay, social commentary over. Back to the problem!
Background: Data
To get started, I will very briefly introduce interval censored data. This data occurs when an outcome is not necessarily known exactly, but rather up to an interval. For example, suppose we have a piece of machinery that is inspected periodically by a mechanic. If at inspection time t1, a given component is intact, but at t2 it is broken, we only know that the component broke sometime in the interval (t1,t2). As such, interval censored is typically represented as (L, R) for each response, where L represents the left side of the interval and R is the right.
Background: Estimator
The canonical estimator for simple interval censored data is the Non-parametric Maximum Likelihood Estimator (NPMLE). For some, the easiest way to introduce this is as a generalization of the Kaplan-Meier curves that also allows for interval censoring. If you are not familiar the Kaplan-Meier curve, we'll start from the beginning: we are fitting the CDF that maximizes the following likelihood function:
Before I start in on this, I will state my biases on gradient descent as a general method. Many computational statisticians are annoyed with the recent rise in popularity of the method, almost certainly due to Andrew Ng's Coursera courses on Neural Networks and it's world-wide popularity. On the other hand, many of those who consider themselves data scientists love the algorithm; it's kind of a one-size-fits-all algorithm (seeing "one-size-fits-all" as a good think vs. a bad thing may be a defining difference between statisticians and data scientists?), typically of order O(nk) per iteration in most problems, easily run in parallel and easy to implement. I suppose I sit in middle of these views; I agree with the statisticians that in general, it is a very simplistic, inefficient, undeservingly popular algorithm at this moment in time. However, I also believe there are plenty of people that consider themselves data scientists, use gradient descent and it's the right thing to do for that problem. I clearly don't hate the algorithm too much, as I put my name on an algorithm that has a constrained gradient ascent step in it.
Okay, social commentary over. Back to the problem!
Background: Data
To get started, I will very briefly introduce interval censored data. This data occurs when an outcome is not necessarily known exactly, but rather up to an interval. For example, suppose we have a piece of machinery that is inspected periodically by a mechanic. If at inspection time t1, a given component is intact, but at t2 it is broken, we only know that the component broke sometime in the interval (t1,t2). As such, interval censored is typically represented as (L, R) for each response, where L represents the left side of the interval and R is the right.
Background: Estimator
The canonical estimator for simple interval censored data is the Non-parametric Maximum Likelihood Estimator (NPMLE). For some, the easiest way to introduce this is as a generalization of the Kaplan-Meier curves that also allows for interval censoring. If you are not familiar the Kaplan-Meier curve, we'll start from the beginning: we are fitting the CDF that maximizes the following likelihood function:
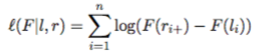
The only restriction is that F must be a non-decreasing function whose range is [0,1] (in other words, the only restriction is that F is a valid CDF). Unlike the Kaplan Meier curves, the estimate is not in closed form! I'm going to skip over some theorems for the sake of brevity, but I hope the reader will trust me in that the final mathematics will boil down to the following:
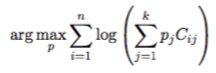
where C is a matrix of 0's and 1's. Side note: a special structure of this particular matrix that I take advantage of for fast computation is that all the 1's for each row are in a single contiguous block for each row. This allows the EM-update to be done in linear time (I've submitted a paper on this that at the time of this writing is still in review. Don't scoop me, bro!). But that's not of too much importance at the moment. Perhaps just remember that all steps of the algorithms used can be done in O(n) by being clever.
Now, those that are just here for the math and don't care about interval censoring may be happy to recognize this as a special case of a mixture model, in which the density for each component is always either 0 or 1 (I want to call this a "binary mixture model", but I currently have no idea if that would be a meaningful title for anyone but me). So that means we can use the EM algorithm to calculate the estimate of p! Yay!
Background: Algorithms
As stated above, the EM algorithm can be used to calculate p. It is worth noting that k, the length of p, can be quite large (up to n). Those with a lot of experience with the EM algorithm probably have guessed that the vanilla EM algorithm can actually do very poorly in this situation. In particular, it can take a lot of iterations to converge. To improve on the process, an Iterative Convex Minorant (ICM) step is added to the algorithm. It is unlikely that this reader has not heard of this algorithm, but here it is in a nutshell: we approximate the target function with a second order Taylor approximation, in which the off diagonals of the Hessian matrix are ignored. This quadratic function is maximized, under the constraint that the parameters are strictly increasing, using the Pool Adjacent Violators Algorithm (PAVA). This is also all done in linear time.
Key note: this ICM step is very efficient and can handle the "heavy lifting" of the algorithm , except in the special case that there are rows of C that only contain a single 1 (this usually corresponds to data that is not censored, but is a little more nuanced than that). As such, the EM + ICM algorithm is a very efficient algorithm. This is implemented in icenReg (starting with v1.3.4) with the ic_np function.
Comparing Gradient Ascent and the EM algorithm
Whew, that was a lot of background! But I still haven't mentioned gradient ascent at any point. How am I going to make a comparison?
Well, as it turns out, the EM algorithm cannot be generalized to the case of the semi-parametric model (i.e. adding regression covariates to the problem). The ICM algorithm can, but still suffers the same problem with uncensored data. To handle this, I implemented a constrained gradient ascent step to take the place of the EM algorithm (+1 to constrained gradient ascent for being able to handle more general problems than the EM algorithm). This algorithm is called by ic_sp. Well, if we use ic_sp, but don't include any covariates, we are actually calculating the same NPMLE as computed by ic_np. However, we will be swapping out the EM step of the algorithm with a gradient ascent step, so we can see how they compare with each other!
Now, currently comparing these algorithms will be slightly tricky with the current version of icenReg. There are two reasons for this. First, ic_sp has some overhead for handling covariates (which is unnecessary for the NPMLE). This doesn't affect number of iterations at all, but does cause a significant increase in runtime per iteration. In this case, the required computations required for the EM algorithm and constrained gradient ascent are virtually identical (i.e. theoretically we could get the run time for each iteration of each iteration would be very close, with maybe a 2x advantage for the EM algorithm. A 2x difference in speed is not an interesting amount). Secondly, the EM algorithms are so computationally cheap that ic_np computes 10 EM steps and 1 ICM step in a single iteration of the algorithm. However, in the way the computation is handled in ic_sp, the ICM and constrained gradient ascent are about equally expensive, so an equal number of ICM and constrained gradient ascent steps per iteration are used (although we can alter the number per iteration). To make as a fair a demonstration as possible, I allowed ic_sp to take 10 steps per iteration, meaning it actually calculates 9 more ICM steps than ic_np does. You'll probably just have to trust me that this gives a bias favoring the constrained gradient ascent algorithm when comparing the number of iterations required.
Below, I have produced the results of such a simulation:
> library(icenReg)
>
> set.seed(1)
>
> # simulates interval censored data where event time
> # is distributed as Weibull(2,2)
> # 50% of data is uncensored: this is where ICM algorithm (alone) does terrible!
> simData <- simIC_weib(n = 5000, b1 = 0, b2 = 0, prob_cen = 0.5)
>
> # Fitting with EM-ICM algorithm
> # Note: for each "iteration" of this algorithm, 10 EM steps are computed
> # and 1 ICM step is computed (this is because EM steps are *really*
> # computationally cheap)
> em_fit <- ic_np(cbind(l, u) ~ 0, data = simData)
>
> # Fitting with Constrained Gradient Ascent-ICM algorithm
> # Note: for each "iteration" of this algorithm, 10 Constrained Gradient Ascent
> # steps are computed and *10* ICM steps are computed. So comparing the final
> # number of iterations is a little uneven (unfairly favoring the Constrained
> # Gradient Ascent algorithm)
> cga_fit <- ic_sp(cbind(l, u) ~ 0, data = simData, baseUpdates = 10)
>
> # Comparing iterations used...
> em_fit$iterations
[1] 3
> cga_fit$iterations
[1] 134
> # EM algorithm converged over 40x faster (in terms of iterations)!!
> # And note that this comparison is biased *in favor* of
> # Constrained Gradient Ascent
> # Run time comparison favors EM **much** more, but not really a fair comparison
> # as the gradient ascent algorithm could be specialized to the NPMLE to reduce computation time
>
> # Comparing final log-likelihood
> em_fit$llk - cga_fit$llk
[1] 3.599635e-07
> # Note that the solution from the EM-ICM algorithm
> # is also slightly more accurate (ie higher log-likelihood)
> # However, this difference is ignorable.
Looking at this results, we see that the EM algorithm is much more efficient than the constrained gradient ascent algorithm in this particular case. And that's despite the unfair advantage given to the constrained gradient ascent method!
Now, those that are just here for the math and don't care about interval censoring may be happy to recognize this as a special case of a mixture model, in which the density for each component is always either 0 or 1 (I want to call this a "binary mixture model", but I currently have no idea if that would be a meaningful title for anyone but me). So that means we can use the EM algorithm to calculate the estimate of p! Yay!
Background: Algorithms
As stated above, the EM algorithm can be used to calculate p. It is worth noting that k, the length of p, can be quite large (up to n). Those with a lot of experience with the EM algorithm probably have guessed that the vanilla EM algorithm can actually do very poorly in this situation. In particular, it can take a lot of iterations to converge. To improve on the process, an Iterative Convex Minorant (ICM) step is added to the algorithm. It is unlikely that this reader has not heard of this algorithm, but here it is in a nutshell: we approximate the target function with a second order Taylor approximation, in which the off diagonals of the Hessian matrix are ignored. This quadratic function is maximized, under the constraint that the parameters are strictly increasing, using the Pool Adjacent Violators Algorithm (PAVA). This is also all done in linear time.
Key note: this ICM step is very efficient and can handle the "heavy lifting" of the algorithm , except in the special case that there are rows of C that only contain a single 1 (this usually corresponds to data that is not censored, but is a little more nuanced than that). As such, the EM + ICM algorithm is a very efficient algorithm. This is implemented in icenReg (starting with v1.3.4) with the ic_np function.
Comparing Gradient Ascent and the EM algorithm
Whew, that was a lot of background! But I still haven't mentioned gradient ascent at any point. How am I going to make a comparison?
Well, as it turns out, the EM algorithm cannot be generalized to the case of the semi-parametric model (i.e. adding regression covariates to the problem). The ICM algorithm can, but still suffers the same problem with uncensored data. To handle this, I implemented a constrained gradient ascent step to take the place of the EM algorithm (+1 to constrained gradient ascent for being able to handle more general problems than the EM algorithm). This algorithm is called by ic_sp. Well, if we use ic_sp, but don't include any covariates, we are actually calculating the same NPMLE as computed by ic_np. However, we will be swapping out the EM step of the algorithm with a gradient ascent step, so we can see how they compare with each other!
Now, currently comparing these algorithms will be slightly tricky with the current version of icenReg. There are two reasons for this. First, ic_sp has some overhead for handling covariates (which is unnecessary for the NPMLE). This doesn't affect number of iterations at all, but does cause a significant increase in runtime per iteration. In this case, the required computations required for the EM algorithm and constrained gradient ascent are virtually identical (i.e. theoretically we could get the run time for each iteration of each iteration would be very close, with maybe a 2x advantage for the EM algorithm. A 2x difference in speed is not an interesting amount). Secondly, the EM algorithms are so computationally cheap that ic_np computes 10 EM steps and 1 ICM step in a single iteration of the algorithm. However, in the way the computation is handled in ic_sp, the ICM and constrained gradient ascent are about equally expensive, so an equal number of ICM and constrained gradient ascent steps per iteration are used (although we can alter the number per iteration). To make as a fair a demonstration as possible, I allowed ic_sp to take 10 steps per iteration, meaning it actually calculates 9 more ICM steps than ic_np does. You'll probably just have to trust me that this gives a bias favoring the constrained gradient ascent algorithm when comparing the number of iterations required.
Below, I have produced the results of such a simulation:
> library(icenReg)
>
> set.seed(1)
>
> # simulates interval censored data where event time
> # is distributed as Weibull(2,2)
> # 50% of data is uncensored: this is where ICM algorithm (alone) does terrible!
> simData <- simIC_weib(n = 5000, b1 = 0, b2 = 0, prob_cen = 0.5)
>
> # Fitting with EM-ICM algorithm
> # Note: for each "iteration" of this algorithm, 10 EM steps are computed
> # and 1 ICM step is computed (this is because EM steps are *really*
> # computationally cheap)
> em_fit <- ic_np(cbind(l, u) ~ 0, data = simData)
>
> # Fitting with Constrained Gradient Ascent-ICM algorithm
> # Note: for each "iteration" of this algorithm, 10 Constrained Gradient Ascent
> # steps are computed and *10* ICM steps are computed. So comparing the final
> # number of iterations is a little uneven (unfairly favoring the Constrained
> # Gradient Ascent algorithm)
> cga_fit <- ic_sp(cbind(l, u) ~ 0, data = simData, baseUpdates = 10)
>
> # Comparing iterations used...
> em_fit$iterations
[1] 3
> cga_fit$iterations
[1] 134
> # EM algorithm converged over 40x faster (in terms of iterations)!!
> # And note that this comparison is biased *in favor* of
> # Constrained Gradient Ascent
> # Run time comparison favors EM **much** more, but not really a fair comparison
> # as the gradient ascent algorithm could be specialized to the NPMLE to reduce computation time
>
> # Comparing final log-likelihood
> em_fit$llk - cga_fit$llk
[1] 3.599635e-07
> # Note that the solution from the EM-ICM algorithm
> # is also slightly more accurate (ie higher log-likelihood)
> # However, this difference is ignorable.
Looking at this results, we see that the EM algorithm is much more efficient than the constrained gradient ascent algorithm in this particular case. And that's despite the unfair advantage given to the constrained gradient ascent method!
 RSS Feed
RSS Feed
